
Le fichier robots.txt est un outil essentiel dans l’arsenal de tout référenceur. Une bonne configuration de ce fichier est cruciale car une utilisation hasardeuse de la directive disallow: peut entrainer des petites cata pour votre SEO…
Contrairement à d’autres composants du SEO, les directives contenues dans le fichier sont généralement plus respectées (par les moteurs de recherche, en tout cas) que n’importe quelle autre action (de contenu ou de backlink) que vous mettez en place.
Sommaire
On se rafraichit la mémoire
Situé au niveau de la racine du domaine, c’est-à-dire dans le fichier /robots.txt, le fichier robots.txt est un protocole d’exclusion destiné aux robots d’exploration du Web. Il est conçu pour communiquer les parties d’un site qu’ils sont autorisés et, plus communément, qu’ils ne sont pas autorisés à explorer. Cela se fait en définissant des directives de crawl.
Les directives d’exploration sont indiquées par la syntaxe « Disallow : » ou « Allow : », qui vous permet d’indiquer quelles URL de votre site sont autorisées à être explorées. Les directives d’exploration doivent ensuite être associées à un agent utilisateur cible, c’est-à-dire « User-agent : », afin de constituer les règles que les robots d’exploration doivent respecter.
Voici un exemple de règle robots.txt que l’on trouve généralement sur un site WordPress ;
Utilisateur-agent : *
Disallow : /wp/wp-admin/
Allow : /wp/wp-admin/admin-ajax.php
Ici, tous les agents utilisateurs sont ciblés, comme l’indique le symbole de l’astérisque. Deux directives suivent ensuite, la première indiquant qu’il ne faut pas explorer le répertoire /wp/wp-admin/, la seconde annulant la première directive disallow, mais uniquement pour l’URL suivante : /wp/wp-admin/admin-ajax.php.
Au fond, son objectif et sa configuration sont relativement simples. Cependant, nous sommes encore témoins de certaines idées fausses concernant le fichier robots.txt où des personnes négligent encore son impact sur la présence organique d’un site.
Voici quelques points à retenir avant d’utiliser le disallow pour exclure les URL et les répertoires via le fichier robots.txt.
Quel est le but d’un fichier robots.txt ?
Le fichier robots.txt concerne l’exploration. Ni plus ni moins.
Disallow ne veut pas dire noindex
La directive disallow: a pour but de désavouer une page aux yeux des moteurs de recherche en indiquant qu’il ne faut pas l’explorer. Cependant, une page désavouée par le fichier robots.txt peut toujours se retrouver dans l’index d’un moteur de recherche. La notion de « noindex » (faisant allusion à l’utilisation de la balise meta robots noindex) devient applicable après un crawl et détermine si un élément de contenu doit ou non être inclus dans l’index d’un moteur de recherche.
Google l’explique clairement dans ses conseils ci-dessous :

Exploration vs. indexation
Il est essentiel de comprendre la définition de l’exploration (crawl) et de l’indexation, notamment lorsqu’on les applique aux fichiers robots.txt.
- L’exploration (crawl) est le processus suivi par les moteurs de recherche pour naviguer sur le Web et trouver des informations : c’est là que robots.txt s’applique.
- L’indexation, quant à elle, est le processus qui suit, lorsque les informations nouvelles ou mises à jour sont stockées, traitées et interprétées : c’est là que la notion de balise meta robots noindex s’applique.
L’impact du disallow: sur votre visibilité organique
Bien que le fichier robots.txt soit là pour gérer le trafic d’exploration, il faut tout de même tenir compte de l’impact de la directive disallow: sur la présence de votre site dans l’index de Google.
Nous savons qu’une page non autorisée par le robots.txt peut quand même se frayer un chemin dans l’index : cela a été confirmé et documenté par Google à plusieurs reprises. Lorsque cela se produit, des extraits comme celui-ci se retrouvent dans les SERP :

Mais pourquoi une page bloquée par le robots.txt apparait dans les SERP Google ? 3 raisons peuvent l’expliquer.
- La page est liée via un backlink depuis un autre site.
- La page a déjà été explorée et indexée et la directive disallow a été appliquée après.
- La directive à laquelle la page s’applique a été ignorée (cette situation est de moins en moins fréquente, même si elle est toujours admise).
Ainsi, lorsque Google tente d’indexer à nouveau la page, le contenu est en grande partie indisponible (à l’exception de quelques éléments). La Search Console permet d’identifier facilement ces problèmes en allant dans Couverture > Valide avec des avertissements > Indexée malgré le blocage par le fichier robots.txt.
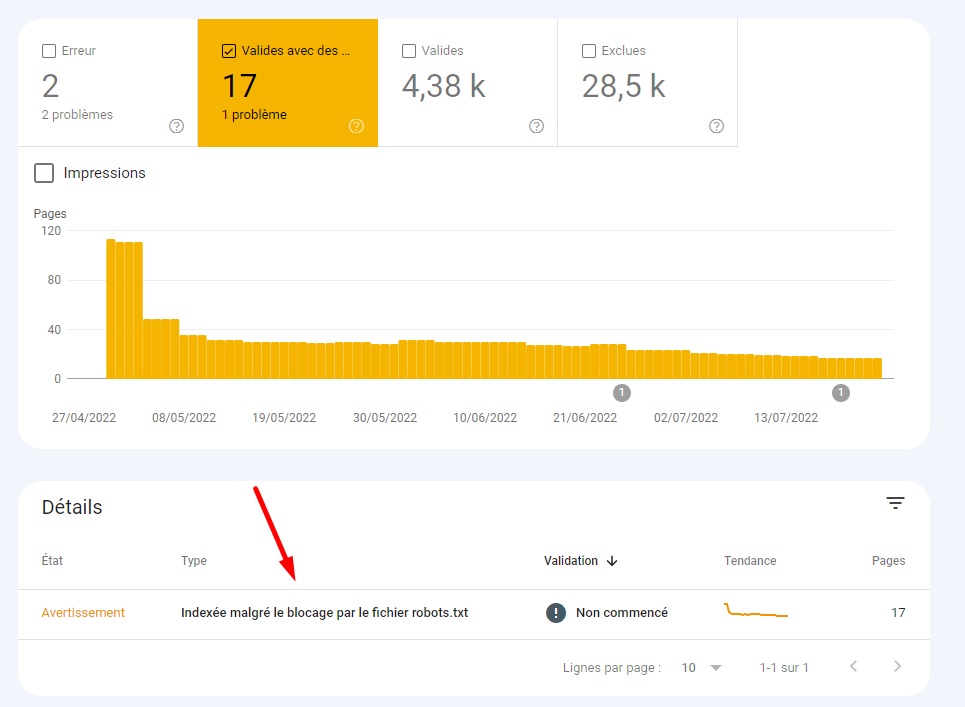
Vous pouvez ainsi déterminer avec précision les URL qui sont bloquées par votre fichier robots.txt mais qui restent accessibles via les recherches Google.
Mais il ne s’agit pas d’erreurs critiques ! Google lui-même les classe comme des avertissements, reconnaissant qu’elles peuvent être intentionnellement configurées de la sorte. Toutefois, s’il s’agit d’une erreur involontaire, il convient d’approfondir l’enquête en examinant individuellement chaque URL bloquée mais indexée.
Ce que vous devez déchiffrer, c’est pourquoi ces URL ont été interdites en premier lieu. Si c’était pour réduire le contenu dupliqué, une solution bien plus optimale est de mettre en place des balises canoniques. Si l’intention était de supprimer entièrement la page de la recherche, une balise meta robots noindex est plus appropriée. Enfin, et c’est sans doute le point le plus important, si une URL a été bloquée par erreur, il convient de résoudre ce problème en supprimant le blocage.
Impact sur la propagation du PageRank
Un autre point à considérer avant d’utiliser le disallow dans votre robots.txt est la façon dont cela empêche la propagation du PageRank. Il est important de garder cela à l’esprit si vous cherchez à introduire des directives robots.txt comme moyen de contrôler l’efficacité de l’exploration.
Par conséquent, si vous souhaitez optimiser votre budget de crawl budget de crawl, considérez bien que la directive nofollow ne transférera pas le PageRank (l’équité de lien) mais que d’autres choses comme les redirections 301 ou les balises canoniques le font.
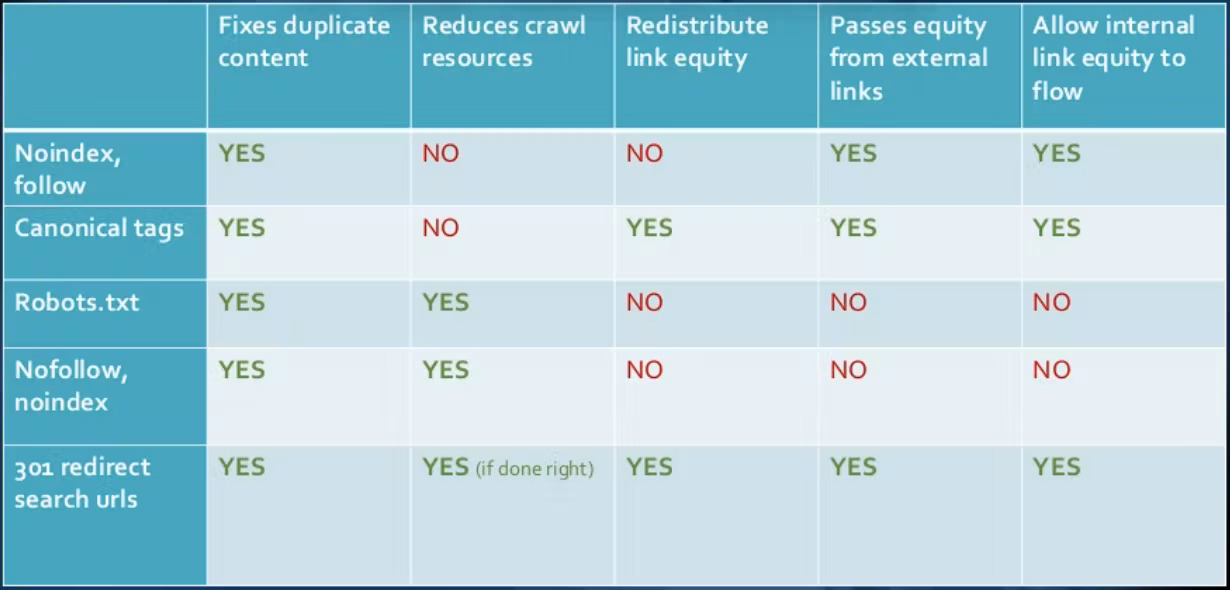
Comme nous pouvons le constater, si les directives d’exclusion via le fichier robots.txt « règlent » les problèmes de contenu dupliqué et améliorent l’efficacité de l’exploration, cette configuration a des conséquences négatives sur les liens internes et entrants.
Ce sont les liens entrants/backlinks qui doivent nous préoccuper le plus, surtout s’ils sont de qualité. L’objectif principal est de s’assurer que ces liens pointent vers des URL capables de redistribuer l’équité des liens/PageRank afin que d’autres pages bénéficient de la popularité.
Pour résumer
Le fichier robots.txt est un outil puissant qui doit être manipulé avec précaution. En règle générale, vous pouvez utiliser ce fichier pour éviter que les user agents ne parcourent du contenu non important, mais même dans ce cas, la définition de « non important » devient intrinsèquement problématique !
Par-dessus tout, il est important de se rappeler les implications que cela peut avoir sur votre présence dans l’index et l’impact de vos backlinks. Considérez toujours toutes les options à votre disposition, telles que la canonicalisation, le balisage meta robots ou même l’authentification http si le contenu que vous cherchez à éloigner des moteurs de recherche est particulièrement sensible ou privé.
Bonjour Gauthier,
Je te remercie pour ce bon article et bonne explication sur le fichier robot.txt Disallow, a utiliser avec précaution et qui a une grande importance en terme de SEO.
Quelles précautions prendre lors de la manipulation du fichier robots.txt pour éviter des conséquences indésirables sur notre présence dans l’index et l’impact de nos backlinks ?