
Le budget d’exploration est un élément que vous devez optimiser pour votre SEO si vous opérez sur un vaste site avec un grand nombre de pages. Dans cet article, nous nous focalisons sur les basiques du budget de crawl, pourquoi est-ce important et comment l’optimiser pour booster votre stratégie de référencement.
Le budget de crawl est un concept qui vivotait dans les cercles fermés des consultants SEO pendant une décennie mais qui, fort heureusement, se démocratise de plus en plus depuis ces dernières années. Quand bien même, il demeure un aspect encore trop souvent sous-estimé dans les stratégies SEO.
👉 Bien que la plupart d’entre vous ayez déjà entendu parler de ce terme et envisagé de vous y pencher, il peut-être parfois difficile d’y identifier les avantages pour la visibilité de votre site. Alors oui, il est vrai que parfois, certains consultants SEO vous diront d’ignorer le budget de crawl ! Mais si votre site est composé de plusieurs milliers de pages (voire beaucoup plus), l’optimisation de votre budget d’exploration représentera un véritable tournant pour votre visibilité organique.
Sommaire
💡 Qu’est-ce que le budget de crawl ?
Le budget de crawl peut être décrit comme le niveau d’attention que les moteurs de recherche accordent à votre site. Ce niveau d’attention est basé sur les ressources allouées par les robots des moteurs pour explorer les pages de votre site web et la fréquence de ces explorations. En gros, la taille de votre site est analysée pour y dédier un niveau de ressources. Si vous gaspillez votre budget de crawl, les moteurs de recherche ne seront pas en mesure d’explorer votre site web efficacement, ce qui finira par nuire à vos performances en matière de SEO.
⚠️ Votre objectif est donc d’assurer que Google dépense son budget de crawl en explorant les pages que vous voulez voir indexées dans les résultats organiques. Pour ce faire, évitez que ce budget soit gaspillé en explorant des pages inutiles pour votre SEO.
Pourquoi les moteurs de recherche attribuent-ils un budget de crawl aux sites web ?
Les moteurs de recherche n’ont pas de ressources illimitées et doivent répartir leur attention sur des millions de sites web. Ils ont donc besoin d’un moyen de hiérarchiser leurs efforts pour parcourir et explorer le Web. L’attribution d’un budget de crawl/d’exploration à chaque site web les aide à y parvenir.
Comment le budget de crawl est-il assigné aux sites web ?
Cela dépend de deux facteurs : le taux limite de crawl (crawl limit) et la demande de crawl (crawl demand).
Le taux limite de crawl
Ce taux vise, pour le moteur de recherche, à établir une limite de pages à explorer en même temps pour chaque site. Si le robot du moteur de recherche n’avait pas de limite d’exploration, il parcourrait toutes les pages d’un site web simultanément, ce qui pourrait surcharger le serveur et impacter l’expérience utilisateur. Les crawlers des moteurs de recherche sont conçus pour éviter de surcharger un serveur web avec des requêtes, c’est pourquoi ils font attention à cet aspect. Mais comment les moteurs de recherche déterminent-ils la limite de crawl d’un site web ? Plusieurs facteurs entrent en compte :
- Une plateforme ou serveur de mauvaise qualité : combien de fois les pages explorées renvoient des erreurs 500 (serveur) ou mettent beaucoup trop de temps pour se charger.
- Le nombre de sites qui tournent sur le même hébergement : si votre site web fonctionne sur une plateforme d’hébergement partagée avec des centaines d’autres sites web, et que vous avez un site web assez important, la limite d’exploration de votre site web est très limitée car elle est déterminée au niveau du serveur. Vous devez donc partager la limite d’exploration de l’hébergement avec tous les autres sites qui y tournent. Dans ce cas, il est préférable d’utiliser un serveur dédié, ce qui réduira les temps de chargement pour vos visiteurs.
La demande de crawl
La demande de crawl/d’exploration consiste à déterminer l’intérêt à réexplorer (recrawler) une URL. En gros, le moteur de recherche va identifier s’il doit visiter régulièrement certaines pages de votre site. Là encore, de nombreux facteurs influencent la demande de crawl, parmi lesquels :
- La popularité : le nombre de liens internes et backlinks pointant vers une URL, mais aussi le nombre de requêtes/mots-clés pour lesquelles elle est positionnée.
- La fraîcheur : la fréquence de mise à jour du contenu de cette page web.
- Le type de page : est-ce un type de page susceptible de changer ? Prenez par exemple une page de catégorie de produits et une page de conditions générales. Laquelle, à votre avis, change le plus souvent et mérite d’être explorée plus fréquemment ?
👍 Pourquoi le budget de crawl est-il essentiel pour votre SEO ?
L’objectif est de vous assurer que les moteurs de recherche trouvent et comprennent le plus grand nombre possible de vos pages indexables, et qu’ils le fassent le plus rapidement possible. Lorsque vous ajoutez de nouvelles pages et que vous mettez à jour des pages existantes, vous voulez probablement que les moteurs de recherche les trouvent tout de suite… En effet, plus vite ils auront indexé les pages, plus vite vous pourrez en bénéficier en termes de visibilité SEO !
⚠️ Si vous gaspillez votre budget d’exploration, les moteurs de recherche ne pourront pas explorer votre site web efficacement. Ils passeront du temps sur des parties de votre site qui n’ont pas d’importance, ce qui peut avoir pour conséquence de laisser des parties importantes de votre site non découvertes. S’ils ne connaissent pas les pages, ils ne les exploreront pas et ne les indexeront pas, et vous ne pourrez pas leur attirer des visiteurs par le biais des moteurs de recherche.
Pour résumer, le gaspillage du budget de crawl nuit à vos performances SEO !
Rappel : le budget de crawl n’est généralement un sujet de préoccupation que si vous avez un site web de grande taille, disons 10 000 pages et plus.
Maintenant que nous avons fait le tour concernant la définition et les enjeux liés au budget de crawl, voyons comment vous pouvez l’optimiser facilement pour votre site.

✅ Comment optimiser votre budget de crawl ?
A travers cette checklist, vous devriez être en mesure d’avoir les bonnes fondations pour permettre aux moteurs de recherche d’explorer vos pages prioritaires.
Simplifiez votre architecture de site
Nous vous conseillons d’adopter un structure simple, hiérarchique et compréhensible pour vos visiteurs et les moteurs de recherche. Par conséquent, hiérarchisez vos niveaux de pages par importance en organisant votre site par niveau et typologie de pages :
- Votre page d’accueil en tant que page de niveau 1.
- Les pages catégories en tant que pages de profondeur de niveau 2. (qui peuvent se compléter aux pages générées par des tags)
- Les pages de contenu ou les fiches produits (pour les e-commerces) en tant que pages de niveau 3.
Bien entendu, des sous-catégories peuvent s’intercaler entre les catégories et les pages de contenus/fiches produits à travers un autre niveau. Mais vous comprenez le principe… l’objectif est d’offrir une structure claire et hiérarchique pour les moteurs de recherche, afin qu’ils comprennent quelles pages sont à explorer en priorité.
Une fois que vous vous serez assurés d’avoir bien établi votre hiérarchie descendante sur votre site à travers ces templates de pages, vous pourrez organiser vos pages autour de thématiques communes et les connecter via des liens internes.
Surveillez le contenu dupliqué
Nous considérons comme dupliquées, les pages qui sont très similaires, ou totalement identiques au niveau de leur contenu. Ces contenus dupliqués peuvent être générés par des pages copiées/collées, des pages de résultats provenant du moteur de recherche interne ou des pages créées par des tags.
Pour revenir au budget de crawl, vous ne voulez pas que les moteurs de recherche passent leur temps sur des pages de contenu dupliqué, il est donc important d’éviter, ou tout au moins de minimiser, le contenu dupliqué de votre site.
Voici comment y parvenir :
- Mettez en place des redirections 301 pour toutes les variantes de votre nom de domaine (HTTP, HTTPS, non-WWW et WWW).
- Rendez les pages de résultats de recherche interne inaccessibles aux moteurs de recherche en utilisant votre fichier robots.txt.
- Utilisez les taxonomies comme les catégories et les tags avec prudence ! Encore trop de sites utilisent les tags à outrance pour marquer le sujet de leurs articles, ce qui génère une multitude de pages tag proposant les mêmes contenus.
- Désactivez les pages dédiées aux images. Vous savez… les fameuses pages du fichier joint que vous propose WordPress.


Gérez vos paramètres d’URL
Dans la plupart des cas, les URLs avec des paramètres ne devraient pas être accessibles aux moteurs de recherche, car elles peuvent générer une quantité pratiquement infinie d’URL. Les URL avec des paramètres sont couramment utilisées lors de la mise en place de filtres de produits sur les sites e-commerce. C’est bien de les utiliser, mais assurez-vous qu’elles ne sont pas accessibles aux moteurs de recherche !
Pour rappel, voici souvent à quoi ressemble une URL avec un paramètre : https://www.lancome.fr/maquillage/yeux/mascara/?srule=best-sellers
Dans cet exemple, cette page renvoie vers la catégorie des mascaras du site Lancôme qui sont filtrés par meilleures ventes (ceci est indiqué par ?srule=best-sellers).
Comment rendre inaccessible les URL avec des paramètres pour les moteurs de recherche ?
- Utilisez votre fichier robots.txt pour indiquer aux moteurs de recherche de ne pas accéder à ces URL.
- Ajoutez l’attribut nofollow aux liens correspondant à vos filtres. Cependant, veuillez noter que depuis mars 2020, Google peut choisir d’ignorer le nofollow. La première recommandation est donc à privilégier.
Limitez votre contenu de faible qualité
Les pages avec très peu de contenu ne sont pas intéressantes pour les moteurs de recherche. Limitez-les au minimum, ou évitez-les complètement si possible. Un exemple de contenu de mauvaise qualité est une section FAQ présentant des liens pour montrer les questions et les réponses, où chaque question et réponse est consultable via une URL séparée.
Liens cassés et mal redirigés
Les liens cassés et les longues boucles de redirections sont des impasses pour les moteurs de recherche. Tout comme les navigateurs, Google semble suivre un maximum de cinq redirections en chaîne en un seul crawl (ils peuvent reprendre le crawl plus tard). On ne sait pas très bien comment les autres moteurs de recherche traitent les boucles de redirections, mais nous vous conseillons d’éviter complètement les redirections qui s’enchaînent et de limiter l’utilisation des redirections en général.
Bien entendu, il est clair qu’en réparant les liens brisés et en les redirigeant via des redirections 301, vous pouvez rapidement récupérer le budget d’exploration gaspillé. En plus de récupérer le budget de crawl, vous améliorez aussi considérablement l’expérience utilisateur du visiteur. Mais redirigez vos pages réellement importantes pour votre business ! En effet, les redirections, et les chaînes de redirections en particulier, allongent le temps de chargement des pages et nuisent ainsi à l’expérience de l’utilisateur.
👉 Pour identifier facilement vos pages en erreur répondant en 410, en 404 ou pire… en soft 404, rendez-vous dans votre Search Console à travers la section Index -> Couverture puis filtrez sur Exclues.
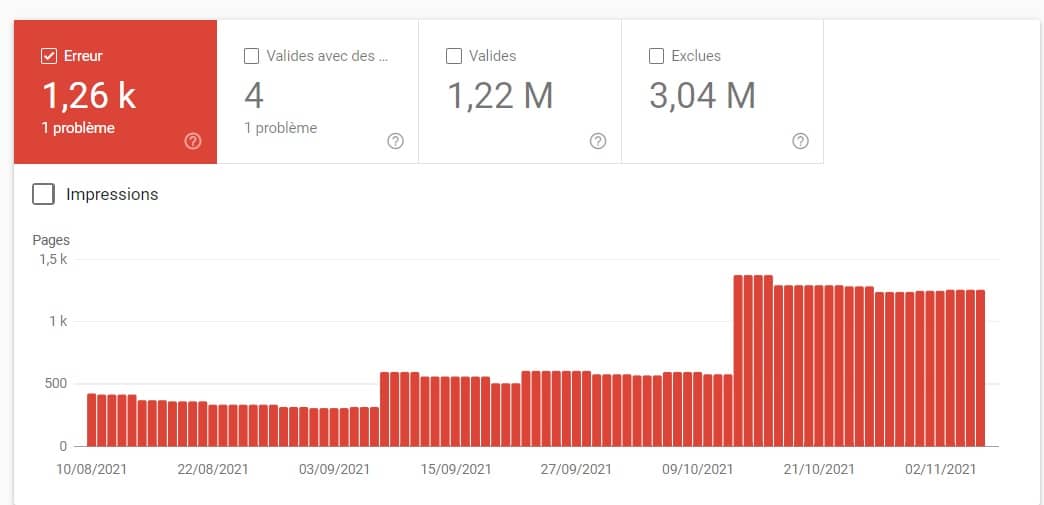
A noter également qu’un outil SEO comme Screaming Frog vous permettra aussi de détecter vos pages en erreur.
URL incorrectes dans les Sitemaps XML
Toutes les URL incluses dans les sitemaps XML doivent être des pages indexables. Les moteurs de recherche s’appuient fortement sur les sitemaps XML pour trouver toutes vos pages, en particulier sur les sites web de grande taille. Si vos sitemaps XML sont encombrés de pages qui, par exemple, n’existent plus ou sont redirigées, vous gaspillez votre budget d’exploration. Vérifiez régulièrement si votre sitemap XML contient des URL non indexables qui n’y ont pas leur place. Faites aussi la démarche inverse : cherchez les pages qui sont exclues à tort du sitemap XML.
💡 Le sitemap XML est un excellent moyen d’aider les moteurs de recherche à dépenser judicieusement leur budget de crawl.
Nos conseils pour optimiser l’utilisation de vos sitemaps XML
Une pratique que nous vous conseillons pour l’optimisation du budget de crawl consiste à diviser vos sitemaps XML en plusieurs sitemaps plus petits. Vous pouvez par exemple créer des sitemaps XML pour chacune des catégories de votre site web. Vous pouvez ainsi déterminer rapidement si certaines sections de votre site web présentent des problèmes.
Supposons que votre sitemap XML pour la catégorie A contienne 500 liens et que 480 soient indexés : vous vous en sortez plutôt bien. Mais si votre sitemap XML pour la catégorie B contient 500 liens et que seulement 120 sont indexés, c’est un problème sur lequel vous devez vous pencher. Vous avez peut-être inclus beaucoup d’URL non indexables dans le sitemap de la section B.
Pages qui chargent trop lentement
Lorsque les pages ont un temps de chargement élevé ou qu’elles renvoient une réponse HTTP 504 indiquant un délai d’attente expiré lors du traitement de la requête, les moteurs de recherche peuvent visiter moins de pages dans le cadre du budget alloué à votre site web pour le crawl. Outre cet inconvénient, les temps de chargement et d’attente élevés nuisent considérablement à l’expérience utilisateur de vos visiteurs, ce qui se traduit par un taux de conversion plus faible.
Les temps de chargement des pages supérieurs à deux secondes sont un problème. Dans l’idéal, votre page se chargera en moins d’une seconde. Vérifiez régulièrement le temps de chargement de votre page à l’aide d’outils tels que Pingdom, WebPagetest ou GTmetrix.
💡 A noter que vous pouvez aussi vérifier votre vitesse de pages à travers Analytics sous la section Comportement -> Vitesse du site, et dans la Search Console à travers la section Signaux Web essentiels, aussi appelés Core Web Vitals, nouveau facteur de ranking SEO à partir de 2021.
De manière générale, vérifiez régulièrement si vos pages se chargent assez vite et, si ce n’est pas le cas, prenez immédiatement des mesures. Le chargement rapide des pages est essentiel à votre succès.
Un nombre élevé de pages non indexables
Si votre site web contient un grand nombre de pages non indexables accessibles aux moteurs de recherche, vous ne faites qu’occuper les moteurs de recherche en leur faisant parcourir des pages non pertinentes.
Nous considérons comme non indexables, ces types de pages :
- Redirections (3xx)
- Pages introuvables (4xx)
- Pages avec des erreurs de serveur (5xx)
- Pages non indexables (pages contenant la balise <meta name= »robots » content= »noindex » /> ou une URL canonique)
Pour identifier facilement ces pages, vous pouvez utiliser Screaming Frog ou, encore une fois, consulter votre Search Console dans la section Index -> Couverture et filtrez sur Exclues.
Un mauvais maillage interne
La façon dont les pages de votre site web sont reliées entre elles joue un rôle important dans l’optimisation du budget de crawl. C’est ce que nous appelons le maillage interne. Mis à part les backlinks, les pages qui ont peu de liens internes attirent beaucoup moins l’attention des moteurs de recherche que les pages qui sont liées par un grand nombre de liens.
Malgré notre premier conseil, évitez une structure de liens trop hiérarchique, les pages de niveau trop profond ayant peu de liens. Dans de nombreux cas, ces pages ne seront pas fréquemment explorées par les moteurs de recherche. Par conséquent, assurez-vous que vos pages les plus importantes reçoivent beaucoup de liens internes. Les pages qui ont été récemment explorées sont généralement mieux classées dans les résultats organiques. Gardez cela à l’esprit et adaptez votre structure de liens internes en conséquence.
Par exemple, si vous avez un article de blog datant de 2010 qui génère beaucoup de trafic organique, assurez-vous de continuer à créer des liens vers cet article à partir d’autres contenus. Comme vous avez produit de nombreux autres articles de blog au fil des ans, l’article de 2010 est automatiquement placé en bas de la structure de liens interne de votre site web.
N’oubliez pas le PageRank !
Remontons un peu dans le temps Marty ! Lors d’une interview datant de 2010 entre Eric Enge et Matt Cutts, l’ancien responsable de l’équipe webspam de Google, la relation entre l’autorité des pages et le budget de crawl a été évoquée. Voici ce qu’expliquait Matt Cutts dans cette entrevue :
« Le nombre de pages que nous parcourons est à peu près proportionnel à votre PageRank. Ainsi, si vous avez beaucoup de liens entrants sur votre page racine, nous allons certainement l’explorer. Votre page racine peut alors contenir des liens vers d’autres pages qui obtiendront un PageRank et que nous explorerons également. Cependant, à mesure que vous vous enfoncez dans votre site, le PageRank a tendance à diminuer. »
Même si Google a abandonné la mise à jour publique des valeurs de PageRank des pages, le PageRank est toujours utilisé dans leurs algorithmes. Comme le PageRank est un terme parfois mal compris, appelons-le l’autorité de page. Ce qu’il faut retenir ici, c’est que Matt Cutts dit en gros qu’il y a une relation assez forte entre l’autorité de la page et le budget d’exploration.
👉 Par conséquent, pour augmenter le budget de crawl de votre site web, vous devez augmenter son autorité (son PageRank). Pour ce faire, il faut en grande partie acquérir plus de liens (backlinks) à partir de sites web externes.
0 commentaires