
Lorsque l’on parle de contenu dupliqué, on sous-entend un contenu très similaire, ou exactement identique, se trouvant sur plusieurs pages d’un même site ou entre plusieurs sites. L’objectif de cet article sera d’identifier les raisons qui peuvent vous générer cette situation et comment la solutionner.
Avant de commencer, nous voudrions préciser que cet article concerne le contenu dupliqué interne (on-site) survenant entre plusieurs pages d’un même site internet et inter-sites (off-site) relatif à un contenu identique publié sur plusieurs sites web. Par conséquent, ces deux types de contenus dupliqués seront pris en considération.
Sommaire
💡 Qu’est-ce qu’un contenu dupliqué ?
Au sens strict, un contenu dupliqué est un contenu très similaire, ou exactement identique, qui se trouve sur plusieurs pages de votre propre site web ou sur d’autres sites web.
D’une manière générale, le contenu dupliqué est un contenu qui n’apporte que peu ou pas de valeur ajoutée à vos visiteurs. Par conséquent, les pages dont le contenu est inexistant ou très mince seront aussi considérées comme des contenus dupliqués.
Vous l’aurez vite compris, vous devez éviter d’avoir du contenu dupliqué car il sème la confusion dans les moteurs de recherche et peut nuire à vos performances en matière de SEO.
👉 Par exemple, avoir une douzaine de pages de contenu dupliqué sur un site web de 100 pages est une chose que vous devriez corriger, mais là où le contenu dupliqué pèsera vraiment sur vos performances SEO est lorsqu’il y en a une quantité excessive !
⚠️ Pourquoi le contenu dupliqué est-il mauvais pour le SEO ?
Les contenus dupliqués sont mauvais pour votre référencement pour trois raisons :
- Lorsqu’il existe plusieurs versions d’un contenu (sur plusieurs pages), il est difficile pour les moteurs de recherche de déterminer quelle page doit être indexée, et de l’afficher ensuite dans leurs résultats de recherche. Cela réduit les performances de toutes les pages intégrant ce même contenu, car elles sont en concurrence les unes avec les autres.
- Les moteurs de recherche auront du mal à établir le degré d’E-A-T (Expertise, Autorité, Confiance) de chaque contenu dupliqué, surtout lorsque des sites web externes renvoient des backlinks vers plusieurs de ces pages. L’autorité sera ainsi diluée vers ces pages dupliquées affichant le même contenu.
- La multiplication de contenus dupliqués sur votre site et donc, de pages non pertinentes, fera gaspiller le budget de crawl qu’allouent les moteurs de recherche pour explorer et indexer les pages de votre site.
🔴 Google inflige-t-il une pénalité en cas de contenu dupliqué ?
Le comportement de Google envers votre visibilité organique sera différent selon le fait que vous soyez coupable de contenu dupliqué entre des pages de votre site ou entre des pages de sites différents.
Contenu dupliqué interne
Le fait d’avoir du contenu en double peut nuire à vos performances SEO, mais vous ne serez pas pénalisé par Google tant que vous n’aurez pas copié intentionnellement le site web de quelqu’un d’autre. Si vous êtes un honnête propriétaire de site web, que vous avez des difficultés techniques et que vous n’essayez pas de tromper Google, vous n’avez pas à vous inquiéter d’être pénalisé.
Contenu dupliqué d’autres sites
En revanche, si vous avez copié sur votre site de grandes quantités de contenu publiés par d’autres personnes sur d’autres sites, vous êtes sur la corde raide. C’est ce que dit Google à ce sujet :
« Dans les rares cas où nous estimons que du contenu en double est peut-être affiché dans le but de manipuler nos classements et de tromper nos utilisateurs, nous apportons également les ajustements appropriés dans l’indexation et le classement des sites impliqués. En conséquence, le classement du site peut être affecté, ou le site peut être retiré définitivement de l’index Google, auquel cas il ne s’affichera plus dans les résultats de recherche. »
Généralement, dans le cas de contenus dupliqués entre plusieurs sites, Google n’inflige pas de pénalités aux sites qui affichent ce même contenu comme il l’est expliqué ci-dessous :
« Le contenu en double n’entraîne pas de conséquences négatives particulières pour votre site sauf si l’objectif semble être de tromper et de manipuler les résultats des moteurs de recherche. En cas de problèmes de contenu en double, et si vous ne suivez pas les recommandations indiquées ci-dessus, nous nous chargeons de choisir la version du contenu à afficher dans nos résultats de recherche. »
👉 En d’autres mots, Google va tenter d’identifier la page/le site qui a publié le contenu le premier afin de le rendre plus visible que les autres ayant repris à l’identique ce contenu. Cela signifie que les pages ayant copié le contenu seront moins bien classées dans SERP (mais sans pénalité) que la page canonique (qui a publié le contenu la première).
🌍 Et le contenu traduit ?
En ce qui concerne un contenu traduit depuis une langue vers une autre, cette pratique n’est pas considérée par Google comme un contenu dupliqué. En effet, les contenus sont bien dans des langues différentes et par conséquent, uniques.
Les causes pouvant entrainer des contenus dupliqués
Les doublons sont souvent dus à un serveur ou un site web mal configuré. Ces cas sont de nature technique et ne donneront probablement jamais lieu à une sanction de la part de Google. Ils peuvent cependant nuire à votre classement organique, c’est pourquoi il est important de les corriger en priorité.
Outre les causes techniques, il existe aussi des causes d’origine humaine : des contenus qui sont délibérément copiés et publiés ailleurs. Comme nous l’avons dit, ils peuvent entraîner des sanctions s’ils ont une intention malveillante.
Le contenu dupliqué généré par des erreurs techniques
Non-www vs www et HTTP vs HTTPS
Supposons que vous utilisiez votre sous-domaine en www avec le HTTPS. Dans ce cas, votre moyen préféré de diffuser votre contenu est via le format https://www.votresite.fr qui sera votre domaine canonique.
Si votre serveur web est mal configuré, votre contenu peut également être accessible par :
- http://www.votresite.fr
- http://votresite.fr
- https://votresite.fr
👉 Choisissez votre moyen principal d’afficher votre contenu, et mettez en place des redirections 301 sur les adresses URLs non privilégiées qui mènent à la version choisie : https://www.votresite.fr
Structure d’URL : les slashes et les majuscules
Pour votre indexation, le contenu dupliqué et la compréhension que Google aura de votre site, vos URL jouent un rôle important. Cela signifie que https://votresite.fr/url-a/ et https://votresite.fr/url-A/ sont considérées comme des URL différentes. Lorsque vous créez vos formats d’URL, il est facile de faire une faute de frappe, ce qui entraîne l’indexation des deux versions de l’URL.
Une barre oblique (/) à la fin d’une URL est appelée un slash. Souvent, les URL sont accessibles par les deux variantes ici : https://votresite.fr/url-a et https://votresite.fr/url-a/.
👉 Veillez donc à choisir votre format préféré d’URL et à rediriger les autres vers ce dernier via des redirections 301.
Pages d’index (index.html, index.php)
À votre insu, votre page d’accueil peut être accessible via plusieurs URL car votre serveur web est mal configuré. Outre https://www.votresite.fr, votre page d’accueil peut également être accessible par :
- https://www.votresite.fr/index.html
- https://www.votresite.fr/index.asp
- https://www.votresite.fr/index.aspx
- https://www.votresite.fr/index.php
Choisissez votre adresse pour servir votre page d’accueil, de préférence https://www.votresite.fr et mettez en place des redirections 301 depuis les autres formats.
Si votre site web utilise l’une de ces URL ci-dessus pour servir du contenu, assurez-vous de les canoniser via des balises canoniques car les rediriger briserait ces pages.
Paramètres de filtres
Les sites web utilisent souvent des paramètres dans les URL afin de pouvoir offrir une fonctionnalité de filtrage sur une liste de produit.
➡️ Prenons un exemple concret.
Ce e-commerce de prêt-à-porter américain de la marque new-yorkaise Ramy Brooke, pour lequel nous avions travaillé sur le levier Google Ads lorsque nous étions chez Labelium Canada, utilise les filtres de manière dangereuse pour leur SEO.
En effet, si vous vous rendez sur leur page Robe : https://www.ramybrook.com/collections/dresses/, vous vous rendrez compte qu’il est possible de filtrer votre sélection par couleur.

Ci-dessus, nous avons donc sélectionné la couleur noire, ce qui a filtré la sélection de produits et créé cette nouvelle URL : https://www.ramybrook.com/collections/dresses/color_black
⚠️ Seulement, si j’applique un autre filtre, en sélectionnant la couleur noire et la taille S, j’obtiendrai quasiment le même listing produits, étant donné que toutes les robes noires sont disponibles dans cette taille. Cela va donc créer une nouvelle URL : https://www.ramybrook.com/collections/dresses/color_black+size_s offrant exactement le même contenu que https://www.ramybrook.com/collections/dresses/color_black
Cette mauvaise gestion des filtres est un générateur quasi illimité de contenus dupliqués.
Bien que cela ne soit pas dérangeant pour les visiteurs, cela peut causer des problèmes majeurs pour les moteurs de recherche. Les options de filtrage génèrent souvent une quantité pratiquement infinie de combinaisons lorsqu’il y a plus d’une option de filtrage disponible. D’autant plus que les paramètres peuvent également être réorganisés.
Pour rappel, ces deux URL montrent exactement le même contenu :
- La catégorie Robe filtrée par couleur noire : https://www.ramybrook.com/collections/dresses/color_black
- La catégorie Robe filtrée par couleur noire et taille S : https://www.ramybrook.com/collections/dresses/color_black+size_s
Pour éviter cette situation, nous vous conseillons de mettre en place des URL canoniques sur toutes les pages avec filtres, pointant vers la page principale non filtrée, afin d’éviter les contenus en double et de consolider l’autorité de la page principale.
💡 Dans notre exemple, les deux URL filtrées auraient une canonique pointant vers https://www.ramybrook.com/collections/dresses/
Cependant, veuillez noter que cela nous vous fera pas économiser de budget de crawl ! En effet, Google continuera à visiter les pages filtrées pour comprendre qu’une balise canonique est en place et ainsi la prendre en compte pour le SEO.
👉 Solutions alternatives :
- Vous pouvez utiliser l’outil de gestion des paramètres URL de la Search Console pour indiquer aux robots d’exploration comment gérer les paramètres.
- Pour nous, la meilleure solution est d’utiliser des dièzes (#) pour construire vos filtres. En effet, le crawler de Google ne prend pas en compte toute information dans l’URL qui se trouve après le #. C’est comme une barrière qui bloque l’exploration. C’est ce qu’applique actuellement La Redoute. En effet, si vous vous trouvez sur la catégorie Pantalon Femme : https://www.laredoute.fr/pplp/100/157878/201/cat-686.aspx et que vous filtrez votre sélection par la taille 48, vous obtiendrez cette URL : https://www.laredoute.fr/pplp/100/157878/201/cat-686.aspx#srt=noSorting&facets=size*40000702_50018150_9900010:48. Comme vous pouvez le constater, toutes les informations qui indiquent la taille sélectionnée se trouvent après le # qui bloque l’exploration des robots des moteurs de recherche. Ainsi, vous économisez du budget de crawl puisque Google ou Bing ne passeront pas leur temps à crawler ces URL.
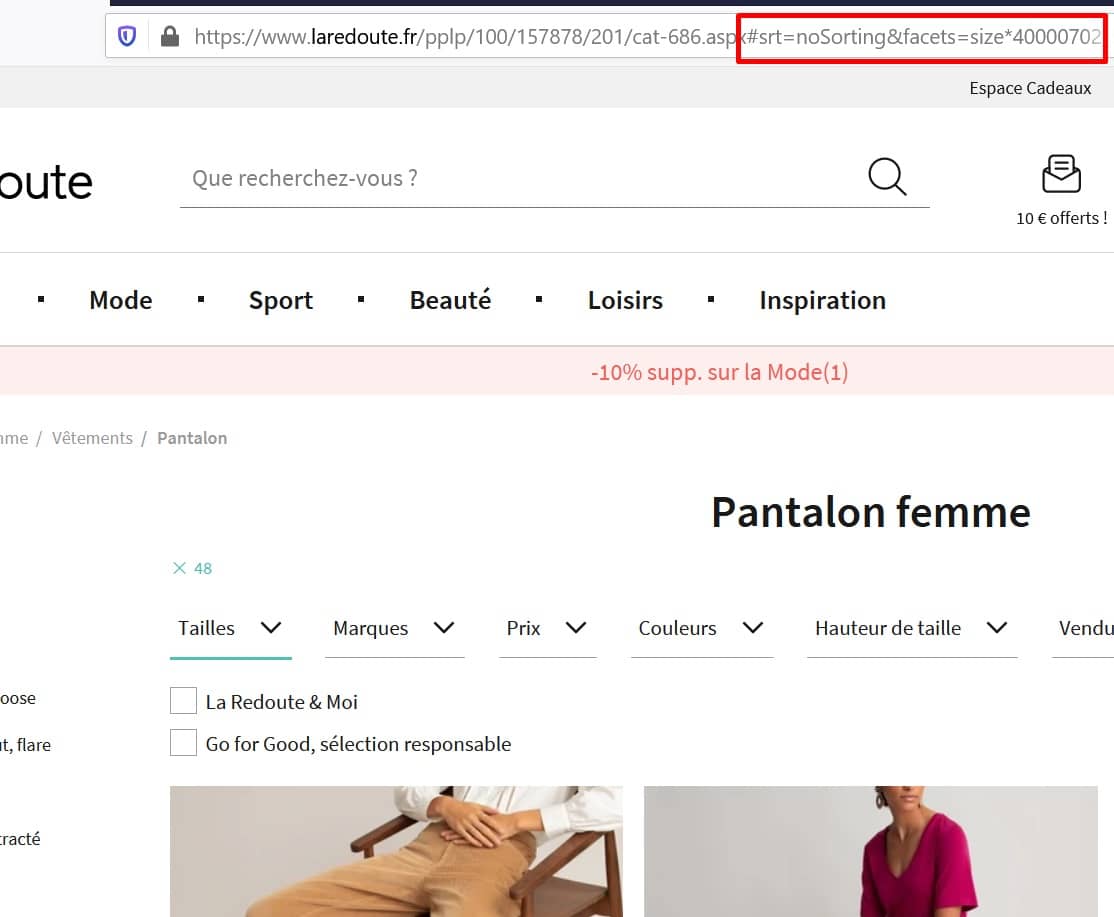
Taxonomies
Une taxonomie est un mécanisme de regroupement permettant de classer le contenu. Elle est souvent utilisée dans les CMS pour gérer les catégories et les balises.
Supposons que vous ayez un article de blog qui se trouve dans trois catégories. L’article de blog peut être accessible dans les trois catégories :
https://www.votresite.fr/category-a/article-camembert/
https://www.votresite.fr/category-b/article-camembert/
https://www.votresite.fr/category-c/article-camembert/
👉 Ici encore, deux solutions :
- Soit vous choisissez une catégorie principale et vous mettez des balises canoniques dans les deux autres URL.
- Mais nous vous conseillons plutôt d’adopter un format d’URL optimisé. Dans cet exemple, au lieu d’une taxonomie qui suit la catégorisation du site et de l’article, optez plutôt pour une URL à une étape : https://www.votresite.fr/article-camembert/ qui vous permettra de placer votre article dans plusieurs catégories sans être embêté par des URL différentes relatives à ces catégories.
Pages dédiées aux images
Certains CMS comme WordPress créent une page séparée pour chaque image. Souvent, cette page ne fait qu’afficher l’image sur une page par ailleurs vide. Comme cette page n’a pas d’autre contenu, elle est très similaire à toutes les autres pages d’images et équivaut donc à un contenu dupliqué.
Si possible, désactivez cette fonctionnalité de création de pages dédiées pour les images. Si ce n’est pas possible, la meilleure solution est d’ajouter un attribut meta robots noindex à la page.

Pages de commentaires
Si vous avez activé les commentaires sur votre site web qui s’affichent en bas des articles ou des fiches produits, il se peut que vous les paginiez/ en chargiez plus automatiquement après un certain nombre. Seulement, ces pages de commentaires paginées afficheront toujours le contenu original de la page (la description du produit ou l’article) : seuls les commentaires du bas seront différents.
Par exemple, l’URL d’un l’article qui montre les commentaires 1-20 pourrait être https://www.votresite.fr/article-camembert, https://www.votresite.fr/article-camembert/commentaires-2 pour l’URL affichant les commentaires 21-40 et https://www.votresite.fr/article-camembert/commentaires-3 pour les commentaires 41-60.
👉 Dans cette situation, nous vous conseillons d’utiliser les balises de pagination link rel=next/prev pour signaler qu’il s’agit d’une série de pages paginées.
⚠️ Attention ! Même si John Mueller a annoncé en 2019 sur Twitter que Google n’utilisait plus les liens de pagination link rel=next/prev, ils sont toujours très utiles ! En effet, cette déclaration fait référence au fait que Google sait parfaitement détecter des pages paginées sans ces balises, cependant elles restent primordiales pour donner des indications claires concernant l’exploration et donc, le budget de crawl. De plus, pour des pages de commentaires, il n’est pas forcément évident d’aller identifier une pagination sans ces balises. Enfin, rappelons que Bing utilise toujours ces balises, ne vous en privez donc pas.
We don't use link-rel-next/prev at all.
— johnmu is not a chatbot yet 🐀 (@JohnMu) March 21, 2019
La localisation
En matière de localisation, des problèmes de duplication de contenu peuvent se poser lorsque vous utilisez exactement le même contenu pour cibler des personnes de différentes régions qui parlent la même langue. Par exemple, si vous avez un site web avec une section dédiée au marché canadien et une autre pour le marché américain, toutes les deux en anglais, il y a de fortes chances que le contenu soit redondant. Google sait le détecter et, en général, il regroupera les résultats. Dans cette situation, l’attribut hreflang permet d’indiquer à Google pourquoi deux sections du site sont proches au niveau de leurs contenus.
👉 En effet, si vous utilisez le même contenu pour différents publics dans le cadre d’une stratégie de SEO international, assurez-vous que l’attribut hreflang soit intégré aux pages pour indiquer que telle ou telle page s’adresse aux Canadiens parlant anglais, une autre aux Canadiens parlant français et une autre aux Américains (parlant anglais, forcément).
⚠️ Attention, les balises hreflang ne vous aideront pas à vous débarrasser de ce contenu dupliqué aux yeux de Google. Pour ce faire, il faudra réellement écrire un contenu unique en anglais pour votre audience canadienne et un autre pour votre audience américaine.
Pages de résultats de recherche interne indexables
De nombreux sites web permettent de faire des recherches à l’intérieur du site via un moteur de recherche interne. Les pages sur lesquelles les résultats de la recherche sont affichés sont toutes très similaires et, dans la plupart des cas, n’offrent aucune valeur aux moteurs de recherche. C’est pourquoi vous ne voulez pas qu’elles soient indexables pour les moteurs.
Empêchez les moteurs de recherche d’indexer les pages de résultats de recherche interne en utilisant la balise meta robots <meta name= »robots » content= »noindex, follow »>. Dans le même temps, il est essentiel de ne pas établir de liens pointant vers ces pages de résultats de recherche interne. Cependant, cette tactique ne vous fera pas économiser de budget de crawl. En effet, la balise noindex indiquera à Google de ne pas indexer ces pages, et pour comprendre cela, son crawler devra les explorer et donc utiliser ses ressources de crawl.
💡 Par conséquent, si un grand nombre de pages de résultats de recherche sont explorées par les moteurs de recherche, il est recommandé d’empêcher ces derniers d’y accéder en premier lieu à l’aide du fichier robots.txt.
Les environnements de test et préprod indexables
Généralement, lorsque vous développez un nouveau site ou lancez une nouvelle version, travailler sur un environnement de test et de préproduction est recommandé. Cependant, ces derniers sont souvent laissés (à tort) accessibles et indexables par les moteurs de recherche.
👉 Ce que nous vous recommandons pour éviter cette situation est d’utiliser l’authentification HTTP pour empêcher l’accès aux environnements de test et de préprod : un avantage supplémentaire est que vous empêchez les utilisateurs d’y accéder également.
Évitez de publier des contenus non finis
Lorsque vous créez une nouvelle page qui contient peu de contenu, enregistrez-la sans la publier, car souvent, elle n’aura que peu ou pas de valeur.
Sauvegardez les pages non terminées sous forme de brouillons : si vous devez publier des pages au contenu limité, empêchez les moteurs de recherche de les indexer en utilisant l’attribut meta robots noindex.
Les paramètres de tracking
Les paramètres sont aussi couramment utilisés à des fins de suivi. Par exemple, lors de campagnes Google Ads, le fait qu’un utilisateur clique sur l’annonce sponsorisée va générer un paramètre de tracking qui s’accolera à l’URL classique de la page. Ainsi, Analytics sera capable d’attribuer cette visite et potentiellement une vente au canal d’acquisition Google Ads.
C’est le cas de cette URL générée lorsque l’on clique sur une annonce Google Ads du site L’Oréal Paris : https://www.loreal-paris.fr/coloration?&wiz_medium=cpc&wiz_source=google&wiz_campaign=oap_goog_ao_haco__gene_search_text_cv_fr__dsa&gclid=Cj0KCQjw8fr7BRDSARIsAK0Qqr7BGGeog1fk8re0fSNnylWnrN3FQyHrWMu9r32kKHP7O3RjtL9ggpYaAuEpEALw_wcB&gclsrc=aw.ds
La meilleure pratique consiste à mettre en place sur la page sans le paramètre (https://www.loreal-paris.fr/coloration), une balise canonique pointant vers elle-même. Si vous l’avez déjà fait, cela résout le problème puisque toutes les URLs avec ces paramètres de tracking sont canonisées par défaut vers version sans paramètres.
Le contenu dupliqué généré par un contenu copié
Pages de destination pour les campagnes SEA
La recherche payante (Google Ads, Facebook Ads…) nécessite des pages de destination (landing pages) dédiées qui ciblent des mots clés spécifiques. Les pages de destination sont souvent des copies de pages originales du site, qui sont ensuite ajustées pour cibler ces mots clés spécifiques. Comme ces pages sont très similaires, elles produisent du contenu en double si elles sont indexées par les moteurs de recherche.
👉 Empêchez les moteurs de recherche d’indexer les pages d’atterrissage en mettant en place des balises noindex. En général, il est préférable de ne pas créer de liens vers vos pages d’atterrissage pour vos campagnes payantes et de ne pas les inclure dans votre Sitemap. Aussi, nous vous conseillons d’utiliser des landing pages déjà présentes sur votre site web et optimisées pour le SEO, puisque normalement, leur contenu sera déjà façonné pour être visible sur des mots-clés pertinents. N’oubliez pas qu’une bonne synergie entre le SEO et le SEA est essentielle dans votre stratégie d’acquisition !
D’autres sites qui copient votre contenu (les salauds !)
Le contenu dupliqué peut également provenir d’autres personnes qui copient votre contenu et le publient ailleurs. C’est notamment un problème si votre site web a une faible autorité de domaine, et que celui qui copie votre contenu a une popularité plus élevée.
⚠️ Les sites web ayant une popularité supérieure sont souvent visités plus fréquemment, ce qui fait que le contenu copié est d’abord visité sur le site web de celui qui l’a copié. Ils peuvent alors être perçus comme l’auteur original et se situer au-dessus de vous dans les résultats de recherche.
👉 Assurez-vous que d’autres sites web vous créditent à la fois en mettant en place une URL canonique menant à votre page et un lien vers votre page. S’ils ne sont pas disposés à le faire, vous pouvez envoyer une demande de suppression de contenu auprès de Google et/ou engager une action en justice.
Copier le contenu d’autres sites web
Si de votre côté, vous copiez un contenu publié sur d’autres sites web que le vôtre, c’est également une forme de contenu dupliqué. Google a documenté la meilleure façon de gérer cela d’un point de vue SEO : un lien vers la source originale, combiné à une URL canonique ou une balise noindex. Gardez à l’esprit que beaucoup de propriétaires de sites web sont réticents à l’idée que leur contenu soit repris, il est donc recommandé de demander l’autorisation de l’utiliser.
🔎 Comment trouver des contenus en double ?
Trouver des contenus dupliqués sur votre propre site web
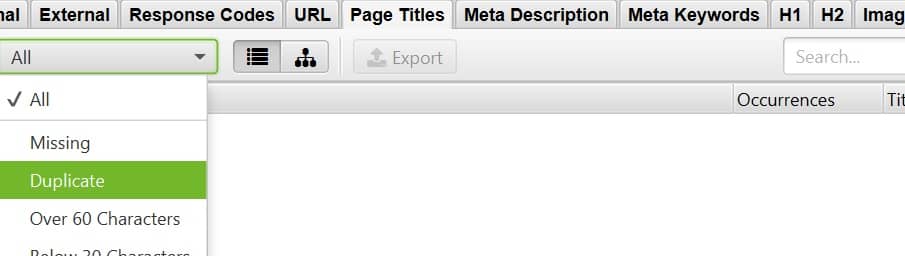
Grâce à Screaming Frog, vous pouvez facilement trouver du contenu en double en vérifiant si vos pages ont un titre, une meta description et une en-tête H1 uniques. Vous pouvez l’identifier facilement en allant dans les onglets Page Titles, Meta Description et H1, puis en filtrant sur Duplicate.
Trouver des contenus dupliqués en dehors de votre propre site web
Si vous avez un petit site web, vous pouvez essayer de rechercher dans Google des phrases entre guillemets. Par exemple, si je veux voir si quelqu’un a copié cet article, je peux chercher une phrase écrite dans le contenu comme « Attention, les balises hreflang ne vous aideront pas à vous débarrasser de ce contenu dupliqué aux yeux de Google. Pour ce faire, il faudra réellement écrire un contenu unique en anglais pour votre audience canadienne et un autre pour votre audience américaine. »
Alternativement, pour les sites web plus importants, vous pouvez utiliser un service en ligne tel que Copyscape. Cet outil parcourt le web à la recherche de plusieurs occurrences du même contenu ou d’un contenu extrêmement proche.
Questions additionnelles
🔨 Corriger le contenu dupliqué va-t-il améliorer les positons SEO ?
Oui, car en corrigeant les problèmes de doublons, vous indiquez aux moteurs de recherche les pages importantes qu’ils doivent réellement explorer, indexer et classer.
Vous empêcherez également les moteurs de recherche de dépenser leur budget de crawl pour votre site web sur des pages dupliquées non pertinentes. Ils peuvent se concentrer sur le contenu unique de votre site web pour lequel vous souhaitez être visible.
👍 Y a-t-il une quantité de contenu dupliqué autorisée ?
Il n’y a pas de bonne réponse à cette question. Cependant, si vous voulez être bien classé dans les SERP avec une page, celle-ci doit avoir de la valeur pour vos visiteurs et un contenu unique.
0 commentaires