
Les modifications apportées au robots.txt, même celles qui concernent l’ensemble du site web, ne se répercutent pas immédiatement sur toutes les URL mais sont appliquées petit à petit.
Une erreur classique et en même temps fatale dans le robots.txt d’un site web est de bloquer par erreur toutes les URLs par disallow : / pour l’exploration/crawl des moteurs de recherche.
Cependant, une telle modification du robots.txt ne se répercute pas immédiatement sur l’ensemble du site, même si une directive concerne toutes les URL. Comme l’a expliqué John Mueller sur Mastodon, il ne s’agit pas de savoir quand Google voit une directive dans le robots.txt, mais quand les URL concernées sont traitées par Google. Si Google rencontre un disallow : /, cela ne se répercutera pas tout de suite sur toutes les URL d’un coup ! Mais commencera à se répercuter URL par URL. Il en va de même pour le statut 404 : dans ce cas, le site web complet n’est pas immédiatement supprimé de l’index. Cela se fait également petit à petit, URL par URL.
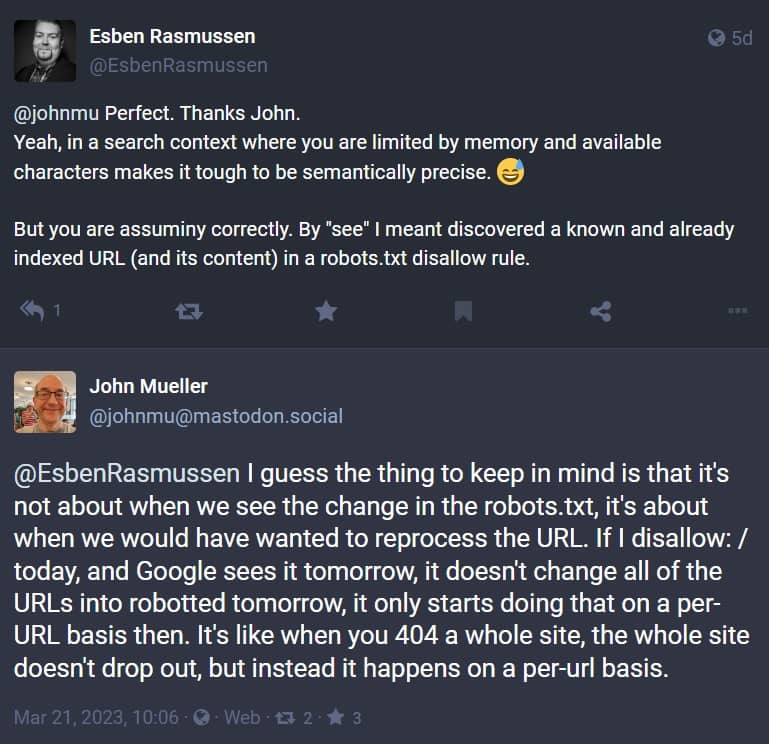
Les URL les plus importantes d’un site web seront les premières concernées car ce sont celles qui sont le plus souvent explorées par Google. Cela signifie qu’après une modification du fichier robots.txt affectant toutes les URL d’un site Web, la page d’accueil et les pages catégories importantes seront probablement traitées en premier.
0 commentaires